Consider the following scenarios.
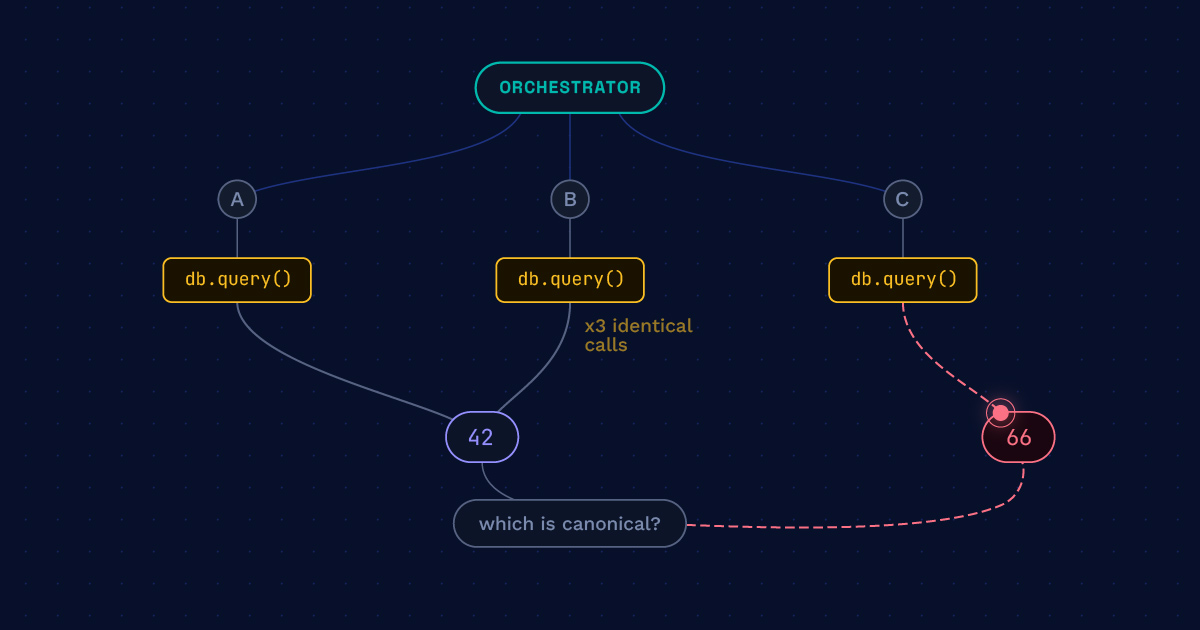
You have three agents in your workflow, operating in parallel. In response to a request, each query your customer database for the same record, returning three slightly different summaries of what they found, and then handing them off to downstream services. The trace shows three clean spans. The bill shows three full passes through your most expensive tool. The final output, assembled by a fourth agent that now has to reconcile the three inputs, picks the most recent summary and discards the rest.
Or: two specialists are given a shared instruction that’s ambiguous in exactly one place. One interprets it as “filter, then summarize”; the other as “summarize, then filter.” Both produce internally consistent outputs. Neither is wrong, but the downstream agent receives two outputs that disagree on which records mattered, and either silently picks one or produces a confident, contradictory recommendation.
Nothing in either scenario throws an exception. The workflow completes, the output is delivered, and nobody knows the system is quietly doing the same work twice or producing inconsistent decisions across branches — until, that is, someone notices the invoice, or the contradictory recommendation reaches a customer.
These are what we refer to as “the coordination tax”. In our recent webinar on the multi-agent trap, it was the second of five failure modes that define AI agent debugging, and it is one of the hardest to surface with standard observability tooling because, structurally, nothing is failing.
What is the coordination tax in a multi-agent system?
The coordination tax is what happens when agents interpret ambiguous instructions differently, producing conflicting outputs, duplicate work, or inconsistent decisions across branches of the same workflow. The failure lives in the gap between what shared context says and what each agent decides it means; the agents themselves are not broken, individually. Each is reasoning correctly given what it received.
The coordination tax is distinct from Compound Reliability Decay, where each agent’s small error compounds across a long chain. The agents under a coordination tax are not making errors; they are making different choices, in good faith, from the same starting state. It is also not an Infinite Retry Loop, where an agent fails to terminate. The coordination tax does not loop; it completes — which is part of what makes it dangerous.
It surfaces in three operational flavors:
- Redundant work. Multiple agents independently doing the same thing — calling the same tool with the same arguments, fetching the same data — because none has visibility into what the others have done.
- Contradictory outputs. Parallel branches producing internally consistent but mutually incompatible results, with no agent in the system aware of the contradiction.
- Decision drift across branches. A shared instruction that produces a consistent decision in dev becomes inconsistent under real input distribution; one agent makes the call one way, another the other way, and the system has no notion of which is canonical.
The tax is paid in tokens, latency, and the erosion of trust. Tokens are the easy one — every redundant call is fully billed. Latency compounds whenever a downstream agent has to reconcile divergence. Trust is the expensive one: a workflow that quietly produces contradictory outputs across runs is harder to debug than one that fails loudly, undermining confidence among engineers and users that they can rely on the system.
Why does the coordination tax compound with agent count?
Every additional agent in a workflow adds two things, not one: capability and coordination surface area. The capability you designed for is the reason the agent is there. The coordination surface area is what you signed up for whether you knew it or not — every new agent is one more interpreter of the shared context, one more potential divergence point, one more place where the same instruction can be read differently.
The math is uncomfortable. A two-agent workflow has one coordination edge. A five-agent workflow might have as many as ten, depending on its topology. The probability that at least one edge produces a divergent interpretation, given any nonzero per-edge probability of divergence, rises faster than the agent count does. This is the structural reason that multi-agent systems tend to become brittle in direct proportion to the scope of their ambition.
Token cost is the easy invoice line. Every redundant call is a full pass through context. Every contradiction discovered downstream is a reconciliation pass that costs again. Teams notice this one because finance notices it.
The harder consequence is silent inconsistency. A coordination tax event does not produce an alert; it produces an output that looks plausible to anyone who didn’t see the other branches. Downstream consumers — humans, other agents, automated systems — cannot detect the divergence because, by the time the workflow completes, only the surviving output reaches them. The contradictory branch is gone, the redundant call is invisible, and the workflow log says success.
Why does standard observability tooling miss the coordination tax?
Because nothing fails.
Logs catch exceptions. The coordination tax does not raise exceptions; it produces valid outputs that disagree. Metrics catch threshold breaches. Latency and error rate stay within bounds because each agent completes its work successfully and within budget. Traces, in the conventional sense, capture spans — and every span is present, well-formed, and apparently healthy. The green dashboard problem is not a bug in dashboard design; it is what a healthy dashboard correctly reports about a system that is structurally producing the wrong work.
The failure is at a layer above the one most observability tools watch. Per-span instrumentation tells you what one agent did. Per-workflow instrumentation tells you whether the workflow completed. Neither tells you whether two agents working on the same task produced compatible results, or whether one agent called a tool a second agent had already called five seconds earlier. That cross-span comparison is the layer where the coordination tax lives, and it is the layer most stacks do not instrument by default.
There is also a subtler version of the problem. Even when you do have spans capturing inputs and outputs at every agent boundary — the precondition for catching this class of failure at all — you still need a deliberate diagnostic pass over those spans to surface the divergence. The trace does not announce itself. It looks fine.
What (and how) you actually have to instrument for the coordination tax
The instrumentation underneath every variant of the coordination tax looks more or less the same: capture what each agent received and what it produced, then assert what should be true across those captures. Apply this at four levels of the workflow, and the failure modes that hide from per-span observability come into sharper view.
Redundant tool-call detection
Within a single workflow execution, watch for multiple agents calling the same tool with semantically equivalent arguments. The signal is implementable today from span attributes alone: tool name, argument hash, workflow ID. The remediation is direct as well: deduplicate the call, or share the result via state. This is the cheapest signal in the section and the most concrete.
Shared-context audit, with consistency assertions on top
At every agent boundary, capture what context the agent received and what it produced on shared state. That captured history answers the standard debugging question after an output goes wrong: did the agent receive bad context, or did it make a bad call against good context? On top of the audit layer, define assertions about when context should be consistent across agents, and report whenever these assertions aren’t met. The audit serves reactive debugging; the assertions serve proactive detection of failures that would otherwise never raise an alert.
Fact propagation between agents
This is the telephone-game version of the tax. Agent A states a fact; Agent B treats the fact as irrefutable; Agent A’s claim may have been partially fabricated. Where the shared-context audit watches system state, this layer watches individual claims as they pass from agent to agent. Instrument for what assertions Agent A made and what Agent B accepted as ground truth, and watch factual accuracy degrade across long chains the same way it degrades in any large organization’s game of telephone.
Graph assertions on workflow structure
When execution branches in parallel, the call graph itself becomes something to instrument. Capture the sequence of calls across branches, and assert prerequisites against it: a downstream task should not start until its prerequisite is observed as complete in the trace; a parallel branch that depends on a shared dependency should not fire before that dependency is observed. These constraints live at the workflow level. They watch structure; the previous three watched content. Same mechanism as the consistency assertions earlier, this time applied to the shape of execution.
Each of the operational flavors named earlier — redundant work, contradictory outputs, decision drift — resolves into one or more of these moves. Redundant work surfaces through the first two. Contradictory outputs surface through the consistency assertions and the fact-propagation layer. Decision drift has no separate mechanism in the list; a decision is one of the things an agent states and another accepts, and the instrumentation above catches it the same way it catches any other claim.
Why coordination tax events keep slipping through triage
Working engineers cannot investigate every alert in their queue. On a good day, a senior engineer can meaningfully look into a handful of issues — three is a number that comes up a lot, and it is roughly right. That ceiling is structural, not a matter of effort or seniority. It is the upper bound of how many incidents one person can hold full context for at once.
Which means triage is a forced-ranking problem, not a coverage problem. Every issue that gets investigated is an issue that was prioritized above the others. And the priorities, in most stacks, are set by what the alerting layer can see: latency spikes, error rate breaches, throughput drops, broken spans. Things that fail loudly.
Coordination tax events do not fail loudly. They do not fail at all, in the conventional sense. They are absent from the alerting layer entirely; when they reach a human, they reach a human as an invoice question, a customer complaint about an inconsistent recommendation, or a slow drift in output quality that takes weeks to attribute. By that point, the originating workflow has run hundreds or thousands of times, and the redundant calls and contradictory branches are scattered across that history.
This is the part of agentic debugging that standard observability is least equipped to handle. The instrumentation is one half of the problem; the prioritization is the other. A platform that surfaces every cross-agent divergence as an alert is not useful — it is noise. A platform that captures the signals but does not rank them puts coordination tax events at the bottom of the queue, behind whatever is throwing exceptions today. Neither helps the engineer who has three slots and needs to spend them on the issues that actually matter.
Surfacing coordination tax events is the solvable half. Surfacing them in a way that competes for attention against the loud failures — that is the harder problem, and the one that determines whether multi-agent systems become maintainable or stay in the category of automation that costs more than it saves.
Frequently asked questions
Prove AI is building solutions to power more correct, explainable and auditable AI outcomes.
We’re always interested in learning about AI management challenges.
Get in Touch

