From the Prove AI Team
Engineering depth, product thinking, and field notes from building the debugging layer for GenAI pipelines.
 PDD series
PDD seriesSpeed is the obvious dividend of cheap prototyping; reach is the real one. What changes when the assistant stops being something you fence in and becomes something you design with?
Latest

A wrong turn should be a rewind, not a restart. Two records — the spec running forward, telemetry running backward — decide which one you get.

Meta’s slowdown says more about production than intelligence.

Vibe coding made building cheap. Spec-driven development was the correction. Prototype-driven development synthesizes both, streamlining iteration while keeping token usage more realistic.

The breakthrough wasn’t better reasoning. It was preventing knowledge from disappearing.

Two mechanisms are driving enterprise LLM bills sky-high: unbounded usage (the loud one finance sees) and context bloat (the quiet one nobody’s measuring). One audit attributes 62% of agentic AI spend to re-sent context — and the model never even needs most of it.
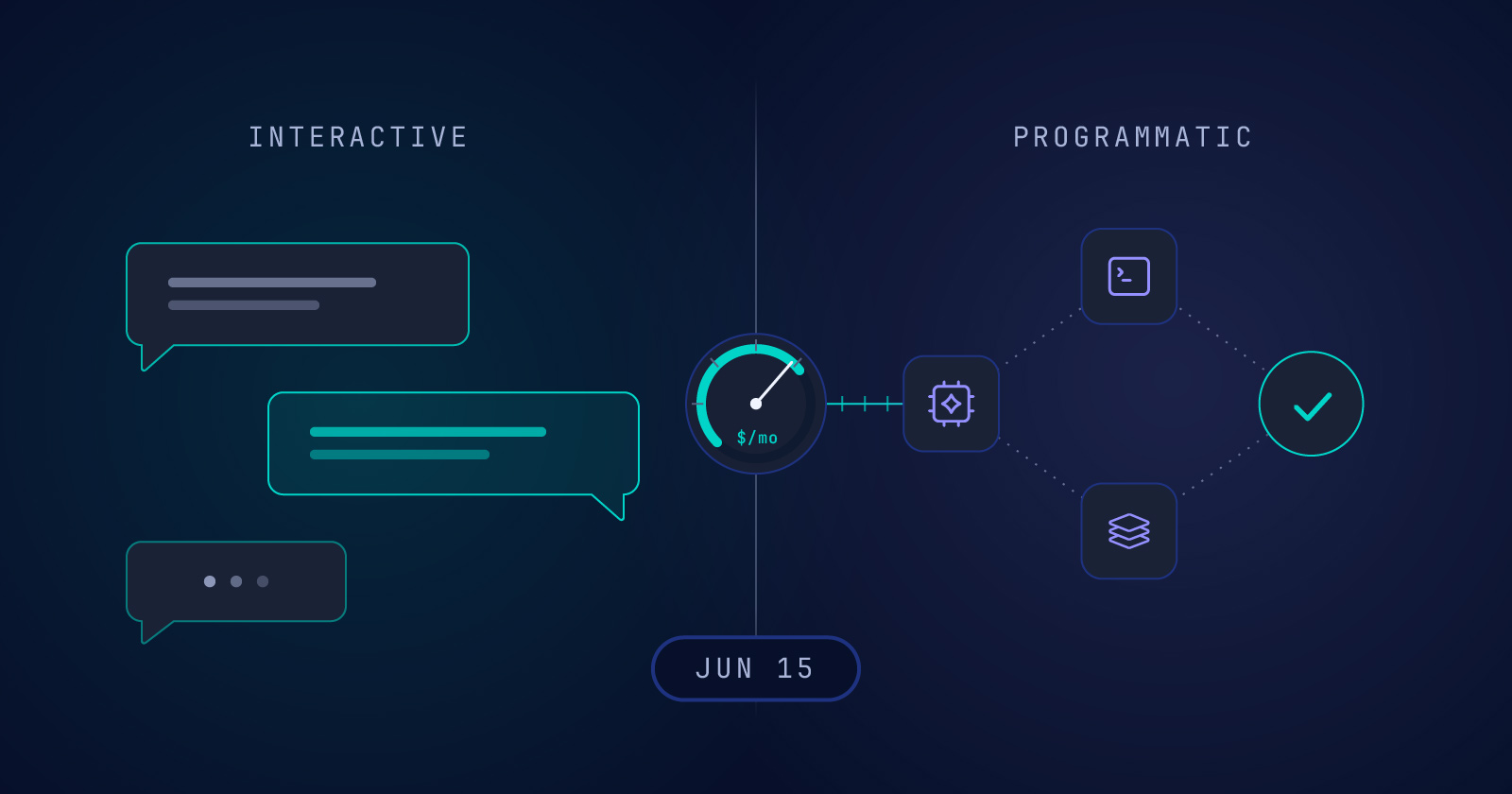
Anthropic's June 15 billing change introduces a fixed Agent SDK credit and nudges production automation toward metered API billing. The mechanics matter; the deeper shift — AI as infrastructure — matters more.
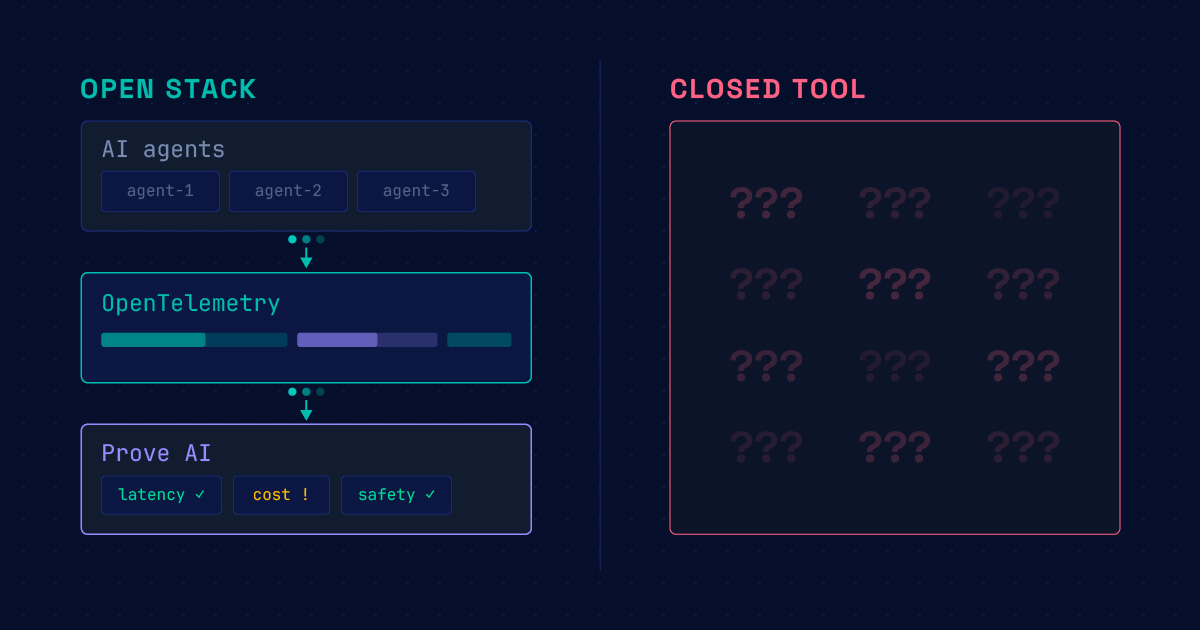
The myth that proprietary code is inherently more secure than open source falls apart on inspection. Hidden blueprints aren’t a security posture — they’re a deferred bill, payable when the vendor changes terms, ships late, or leaves you with no path to a patch.
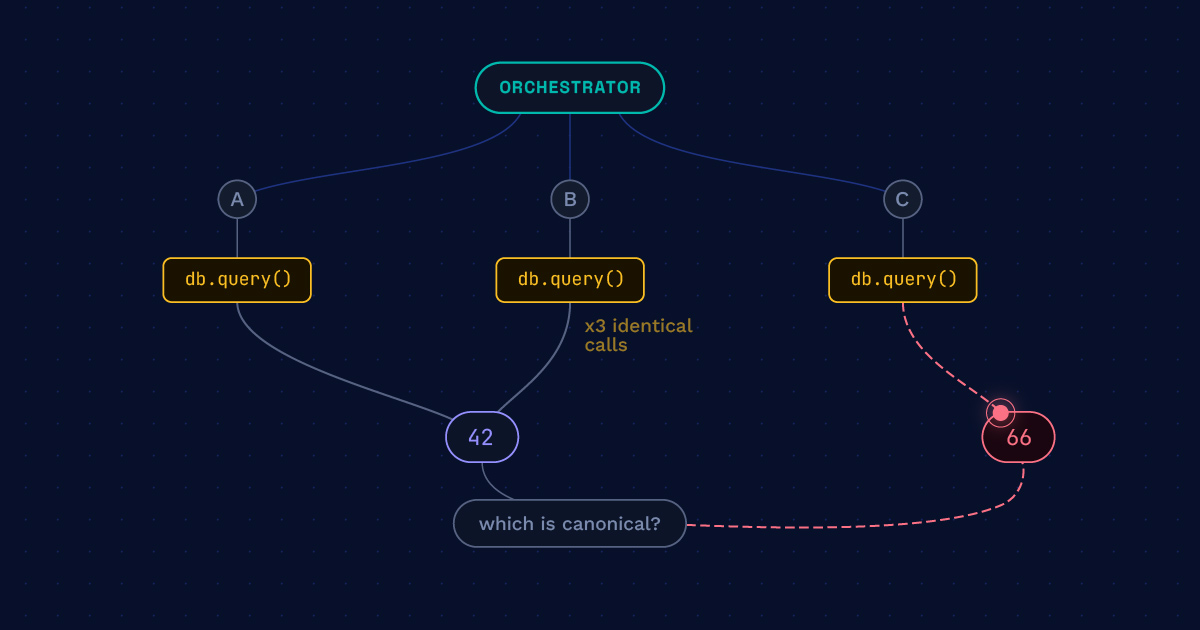
When agents in a multi-agent workflow quietly duplicate work or produce contradictory outputs — and nothing throws an exception — you’re paying the coordination tax.
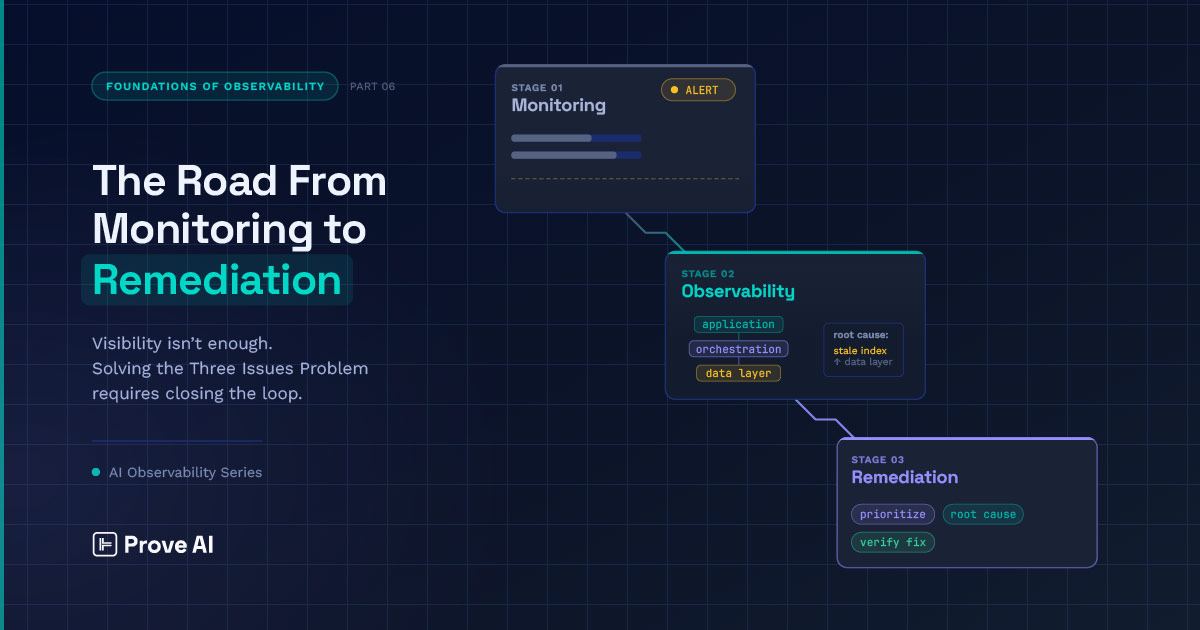
Remediation is the logical next step after observability — surfacing not just what’s broken, but which issues to prioritize and how to fix them. The capstone of the Foundations series.
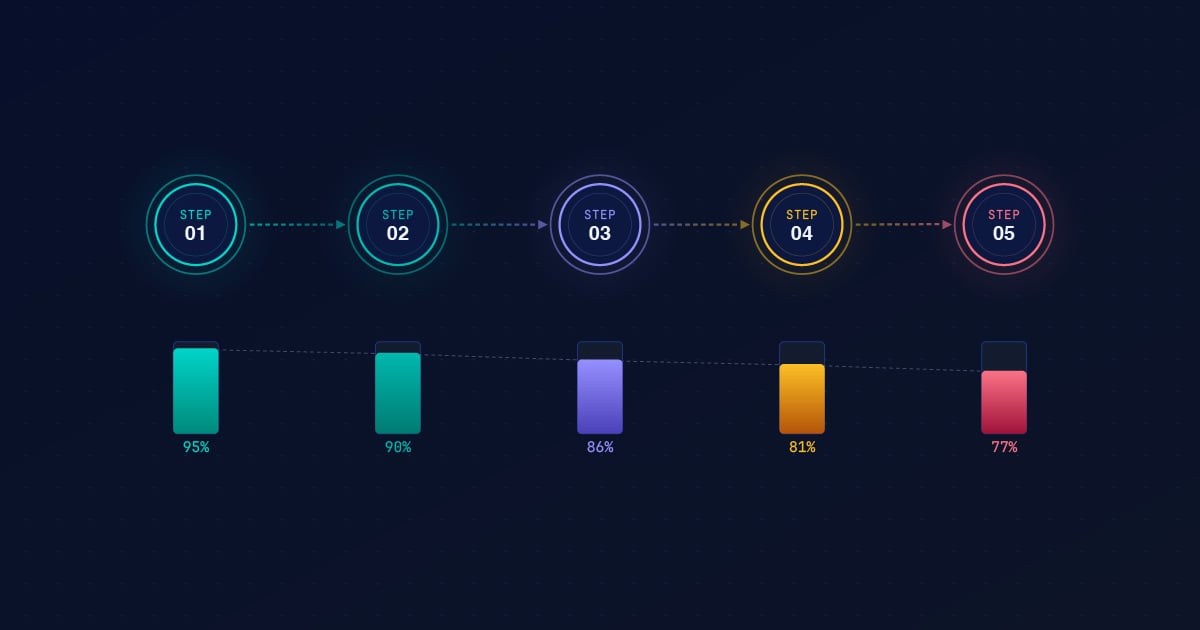
Reliability multiplies instead of adding — so a chain of individually solid steps can still fail most of the time in production. The decay is a function of architecture, not model quality, and the right composition patterns bend it back.
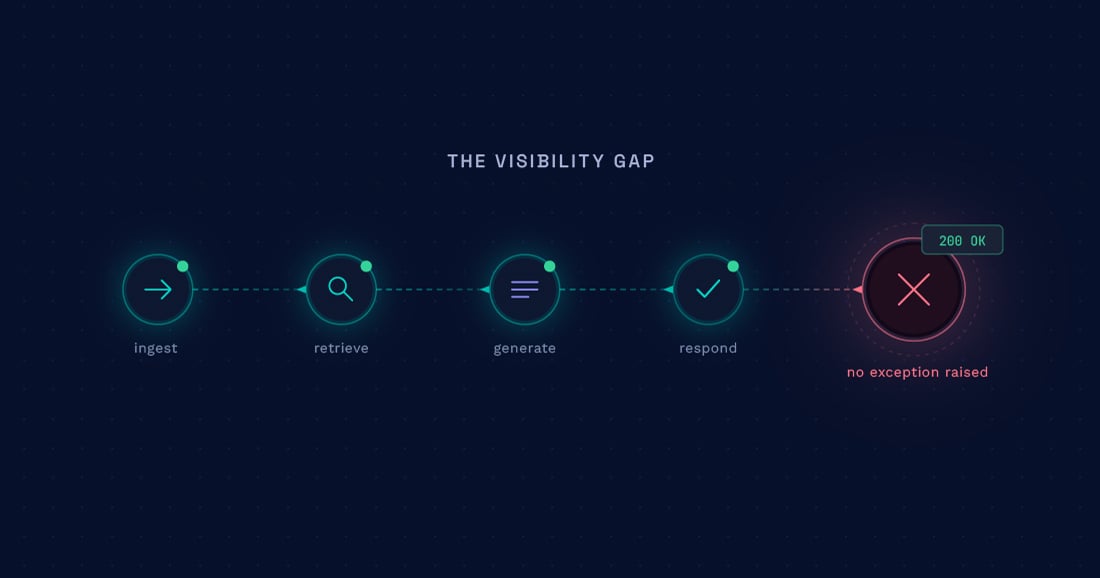
Traditional observability catches execution failures — exceptions, timeouts, 5xxs. But an agent can execute flawlessly and still return the wrong answer, and that’s the gap standard tracing never sees.
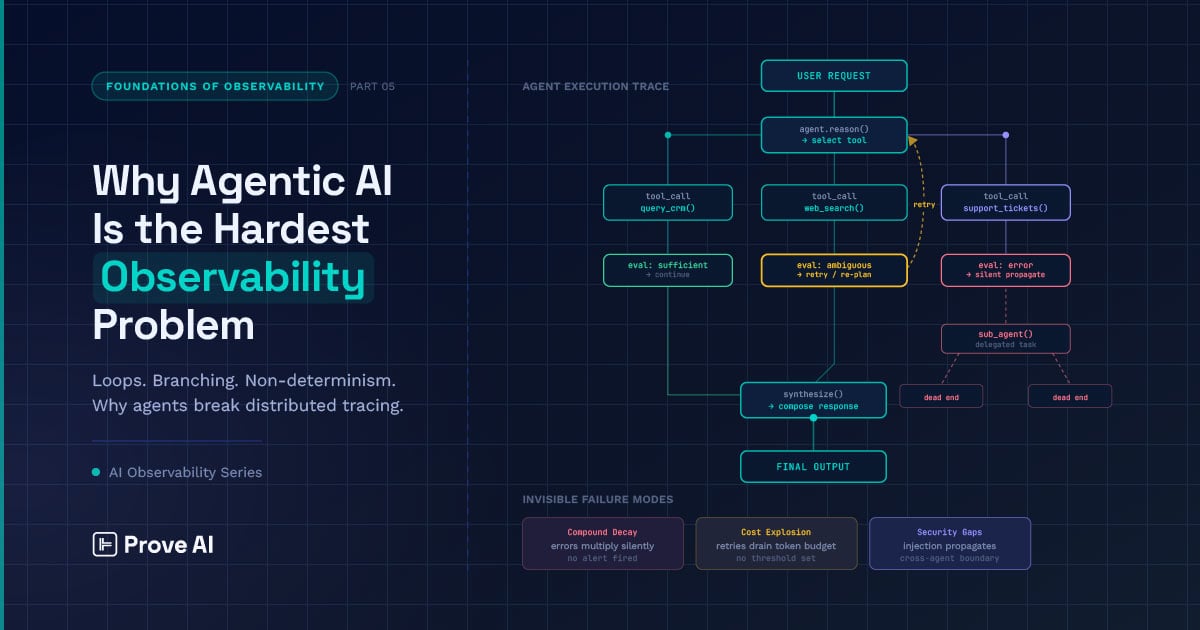
Agentic debugging is the hardest observability problem because agents are non-deterministic, multi-step, and self-correcting — so the real fault often sits several hops upstream of the symptom.
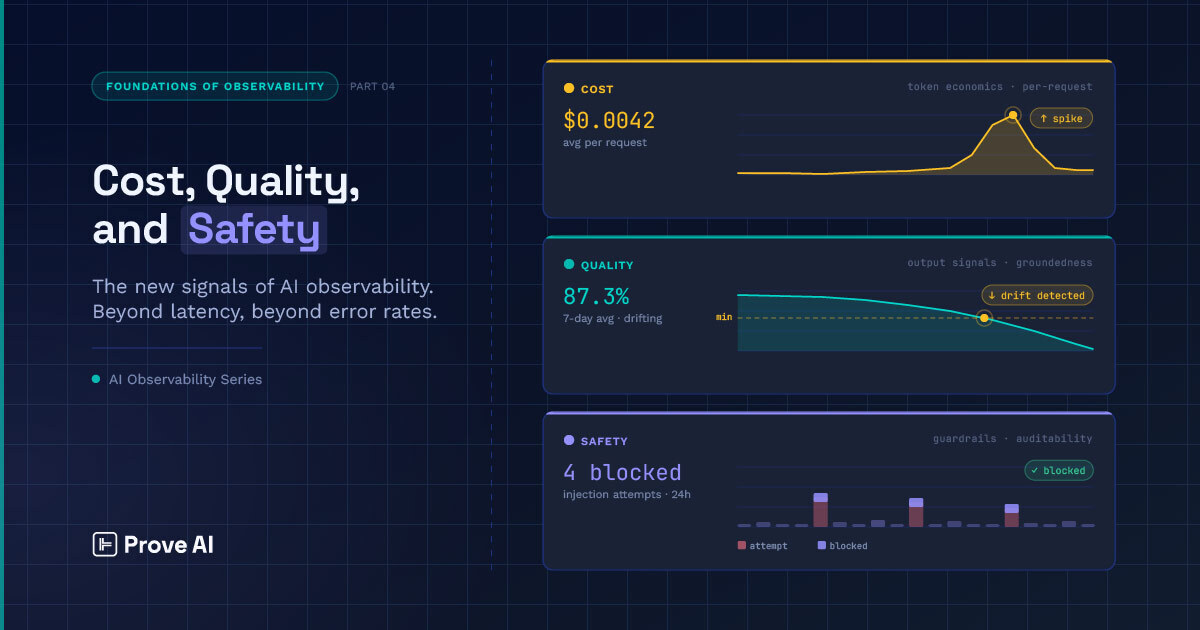
Latency and throughput tell you a system is running — not whether it’s right, affordable, or safe. Cost, quality, and safety are the three signals AI observability has to add.

A working demo is the first 20%. The last 80% — observability, telemetry, and the edge cases that only show up in production — is where teams stall. Prove AI CTO Greg Whalen on the gap.

Reliability isn’t a post-launch fix — it’s decided by the telemetry, governance, and observability you build in before a model ever ships. Prove AI CTO Greg Whalen on getting it right early.
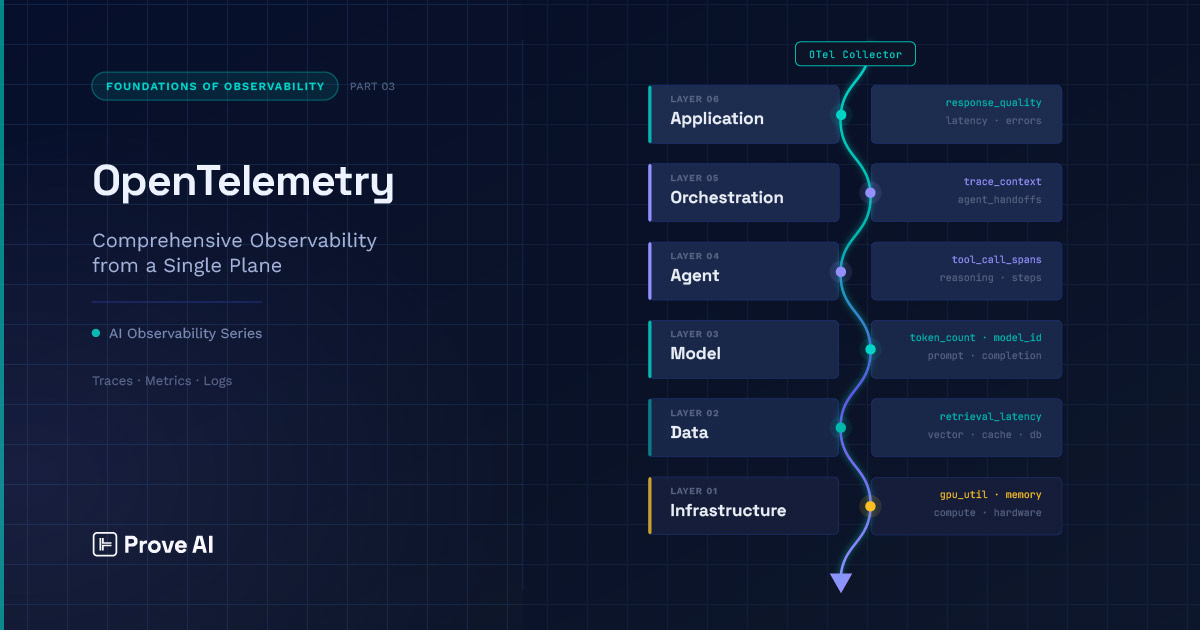
OpenTelemetry gives AI systems one vendor-neutral standard for traces, metrics, and logs — so signals from every layer land in a single plane instead of a dozen disconnected tools.
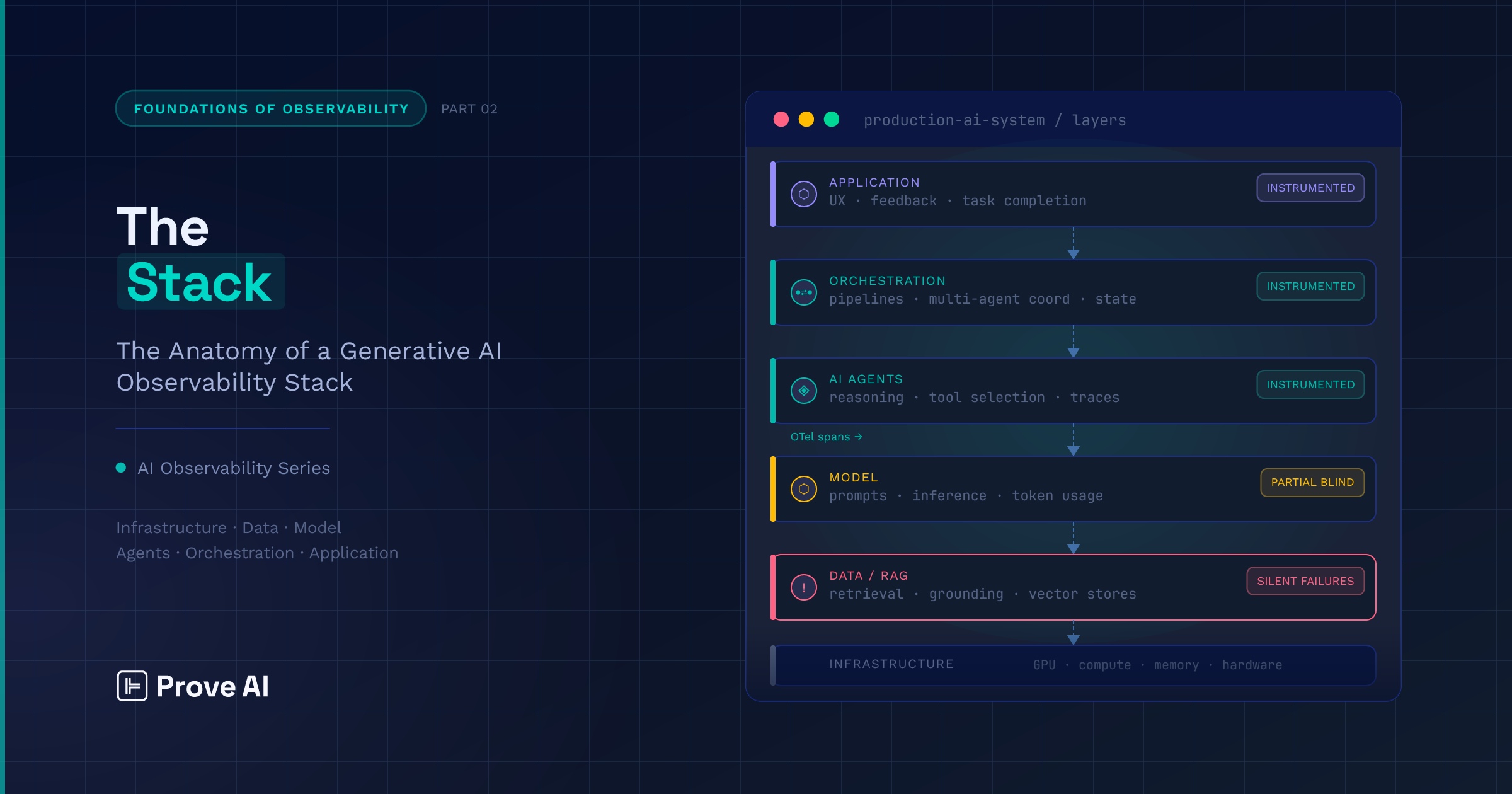
A generative-AI observability stack is six interdependent layers, from infrastructure up to the application — and failures low in the stack surface at the top in disguise. Here’s the blueprint, layer by layer.
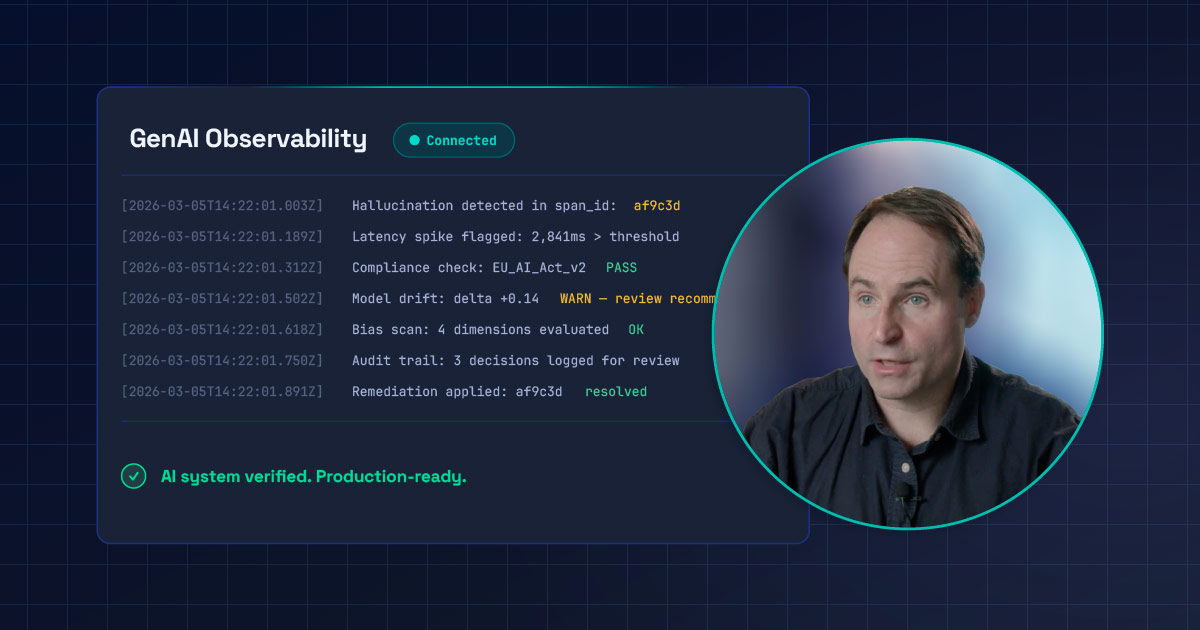
Most AI governance fails because the telemetry underneath it is incomplete or untrustworthy. Prove AI CTO Greg Whalen on why fixing the data layer comes before governing AI.
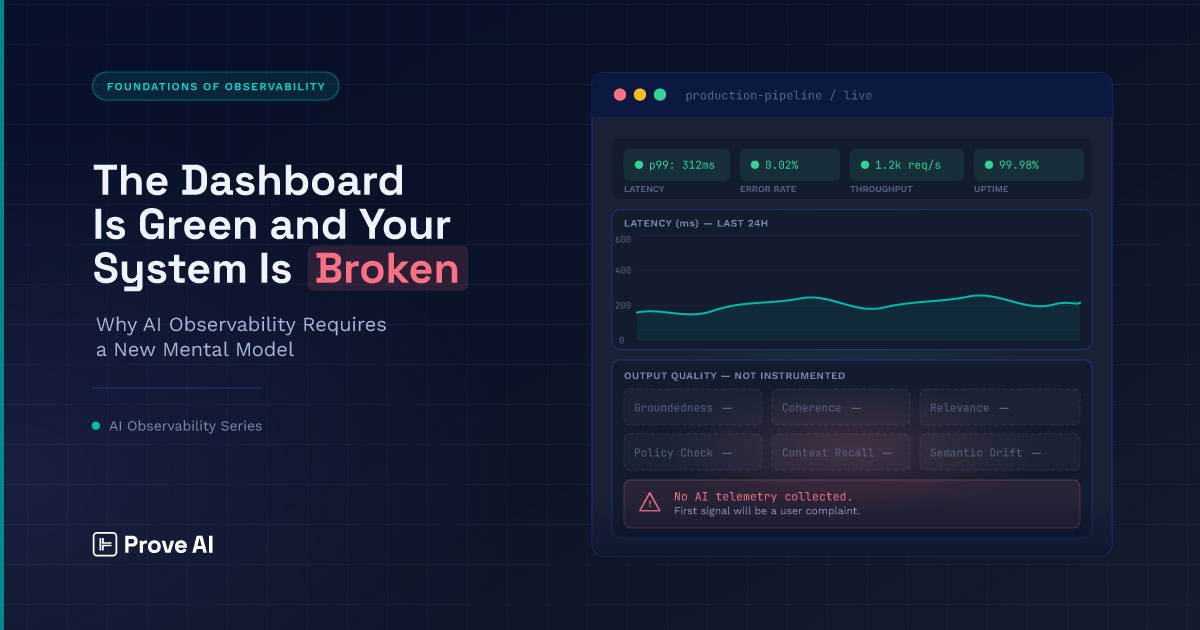
Every dashboard is green — latency, errors, throughput all nominal — yet the model is confidently returning wrong answers. That’s the failure traditional monitoring can’t see.

Prove AI CTO Greg Whalen on the engineering behind trustworthy AI: why observability and governance — not model choice — decide whether a prototype survives production.

The mistake: treating generative AI like traditional software — shipping fast and deferring observability, governance, and debugging until production stalls. Prove AI CTO Greg Whalen on the fix.
Fewer than 5% of GenAI prototypes reach production. The Prove AI white paper lays out the two-phase fix: containerized telemetry infrastructure, then AI-guided agentic remediation.

Production genAI lives or dies on telemetry — yet most teams still collect it with traditional software-observability tools built for a different problem entirely.

The painful debugging cycles we see today stem not from bad models, but from incomplete, mutable, or poorly ordered system data.

As AI crosses from novelty to expectation, CTOs must shift focus from experimentation to building durable, scalable foundations.

Monitoring tells you something changed. The next phase of AI observability turns that signal into action — automated governance and remediation, not just another dashboard.