There’s a persistent myth in enterprise software that open source code is inherently less secure than proprietary alternatives — that visibility into a codebase is a liability, and that keeping source code hidden behind a vendor wall is the safer play. It’s an intuitive argument, and it’s (usually) wrong.
The principle it rests on is commonly summarized in the pithy phrase “security through obscurity.” In essence, this amounts to the claim that systems are safer when their inner workings are concealed. But, Kerckhoffs’s Law — a foundational principle of cryptography dating back to the 19th century — takes the opposite view: a well-designed system should remain secure even when everything about it except the secret key is public knowledge.
We concur with Kerchoff; hiding the blueprint isn’t the way to a robust security posture, and it’s better by far to build something hardened enough that it doesn’t need to be hidden. That’s precisely why we’ve built our AI observability pipeline on open standards, as this is the best way to give engineers the flexibility to build with their tools, on their own terms.
This distinction between open- and closed-source approaches matters more than ever as teams implement increasingly complex multi-agent AI systems. Something like 97% of companies are leveraging open-source AI models in their codebases with little in the way of accompanying visibility, and the reliance on coding assistance has itself driven an additional 30% average increase in the use of open source packages.
Below, we’ll flesh this picture out in more detail, making the case that while open-source software may not be a panacea, it remains an important, security-forward approach to building the code infrastructure on which the modern world (with its skyrocketing number of AI agents) runs.
More Eyes, Faster Fixes
The security case for open source rests on a simple structural reality: when source code is publicly available, more people are looking at it. When a proprietary vendor has a team of ten engineers responsible for security review, those ten engineers and their (presumably) twenty eyes represent all the potential for vulnerability discovery. Open source projects like the Linux kernel have attracted thousands of contributors, which is a scale of scrutiny no closed-source team can match.
This plays out in vulnerability disclosure, too. Open-source communities tend to surface security issues faster, and the reports that emerge are typically more detailed precisely because the reporter can see the code. Suggested fixes often arrive alongside the disclosure itself, compressing the patch cycle in ways proprietary vendors structurally cannot replicate. Closed-source vendors are beholden to budget cycles, release planning, and internal QA processes, meaning that fixes ship when the organization is ready, not necessarily when users need them.
The Vendor Lock-In Problem
The security conversation rarely surfaces the most practical risk of closed-source software: what happens when a vendor decides to change the terms, discontinues a product, or simply goes away.
When Oracle covertly restructured its Java SE subscription model in 2023, organizations found themselves facing licensing costs that were, in many cases, substantially higher than before, a difficulty compounded by the fact that they had no ability to inspect, fork, or self-host their way out of the situation. Users of discontinued proprietary products face a harder problem: they inherit whatever vulnerabilities existed at end-of-support with no path to remediation unless they migrate to a new vendor’s ecosystem entirely.
Open source inverts this dynamic. When code is public and the license permits it, organizations retain the right to audit, modify, and maintain what they depend on regardless of what any single commercial entity decides to do. The community becomes akin to a kind of safety net. Abandoned projects can be forked; critical vulnerabilities can be patched internally rather than waiting on a vendor’s acknowledgment (to say nothing of a fix).
This is particularly acute in AI observability tooling, where the data pipeline itself needs to be trustworthy. If you’re using a closed-source platform to capture telemetry, monitor performance and quality, or catch model regressions, you’re trusting a vendor’s representation of what’s happening inside your infrastructure, with limited (or no) ability to verify the methodology, inspect the throughput collection logic, or validate that the AI metrics you’re acting on are computed the way you think they are. That’s a double-blind problem: a black-box observability tool monitoring a black-box model. Less than ideal, to say the least.
The Real Risks Are Governance Problems
None of this means open source is without risk. Famously, the 2024 discovery of the XZ Utils backdoor demonstrated that even widely trusted compression utilities can become attack vectors. The Log4j incident before it showed how a single vulnerable component could sit unnoticed inside thousands of downstream applications.
But these incidents share a common root cause: governance failures, not open source itself. These teams are running vulnerable versions of components they haven’t inventoried, dependencies that haven’t been updated in years, and with no systematic process for tracking what’s underwriting production deployments of AI agents.
Critically, the same vulnerabilities exist inside proprietary software, with the difference being that they’re often less visible and slower to surface. The appropriate response to these risks is not to retreat to opacity, it’s to invest in better instrumentation, systematic dependency tracking, and a prioritized approach to AI agent remediation.
What This Means for AI Observability
The governance challenge that affects open source software broadly becomes even more pointed for AI systems specifically. Non-deterministic model behavior, multi-layer architectures, and new AI agent signal types around cost, quality, and safety all demand observability tooling that teams can actually trust and inspect.
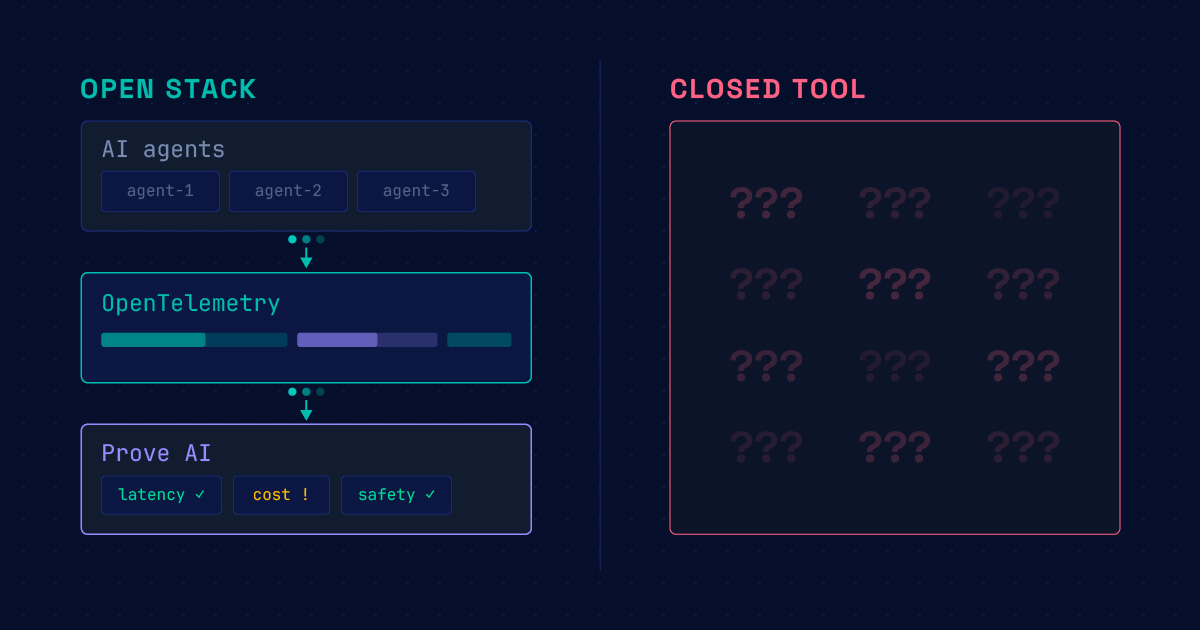
This is the impetus behind Prove AI’s approach to the observability and remediation parts of AIOps. Rather than building proprietary instrumentation from scratch, the platform packages community-hardened open source components — primarily OpenTelemetry and Prometheus — into a containerized distribution that engineering teams can deploy, audit, and extend. The telemetry stack is inspectable by design; the value-add is the debugging and remediation layer on top of it, which allows for data-driven decisions that don’t rely on a proprietary collection mechanism that requires trust by default.
It’s the same model Red Hat proved out for Linux: open source at the foundation, enterprise capability layered above it, and — critically — no vendor capture. The core components are maintained by communities with no interest in locking your data or your agentic workflows to a single commercial relationship.
Visibility Is a Security Posture
Security and observability share the same prerequisite: you can’t act on what you can’t see. Open source provides the visibility layer that offers transparency into the code, into the methodology, into the change history, which allows organizations to make data-driven decisions rather than extend trust on faith. This mattered even when we were building monolithic, deterministic applications, but it is even more important now that we’re prompt engineering these distributed, stochastic multi-agent systems. At the same time, the powerful agentic architectures about which we are all so (justifiably) excited are making it even more difficult to ensure our systems are secure, observable, and high-reliability.
The debate between open and closed source was never really about which one is inherently safer. It was always about who controls the conditions under which you can verify. Open source puts that control in the hands of the people who actually need it.
Frequently asked questions
Prove AI is building solutions to power more correct, explainable and auditable AI outcomes.
We’re always interested in learning about AI management challenges.
Get in Touch

