At long last, we’ve made it to the climax of our Foundations of Observability series. Let’s take a moment to adumbrate the case we’ve made along the way:
- The shift from deterministic to non-deterministic systems has necessitated a new observability stack.
- That AI observability stack produces signals pertaining to quality, cost, and safety that monitoring infrastructure was never designed to surface.
- In multi-agent AI systems, those signals fragment further across tool calls, sub-agents, and retrieval steps, producing new, subtle failure modes that require new, powerful solutions.
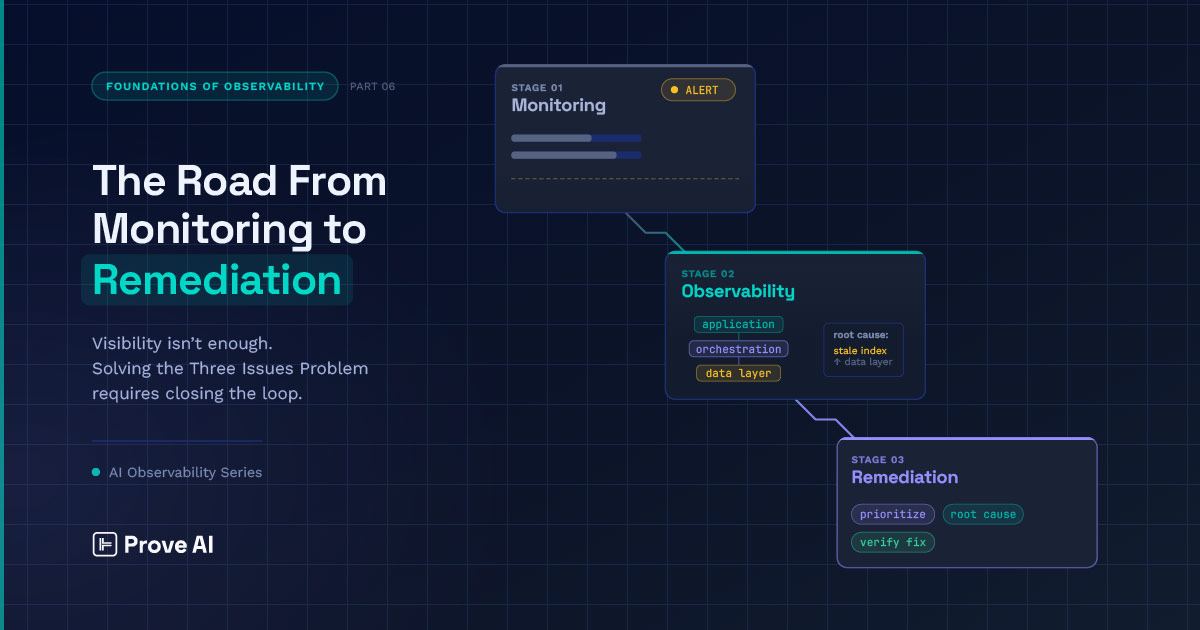
Remediation is the logical next step after observability, telling you which issues to prioritize and offering guidance on how to fix them. The question this post takes up is what this step looks like, and why it has to be oriented around remediation rather than just superior observability.
Monitoring, observability, and AI agent debugging
The distinction between monitoring and observability is well-trodden ground, but it’s worth briefly covering anew to ensure we’re all on the same page and to help us understand how the latter sets us up for debugging multi-agent AI systems.
In the standard account, monitoring tracks predefined metrics against predefined thresholds, while observability is a more pervasive and responsive posture that lets you ask questions you didn’t even know you’d need to ask.
The following table makes this clearer:
| Monitoring | Observability |
|---|---|
| A dashboard showing elevated p95 latency on an agent endpoint | Drilling into a specific agent run, tracing the latency back to a tool-call loop where the planner repeatedly invoked the same retrieval step with slightly varied queries, and identifying that the underlying cause was a low-relevance chunk in the first retrieval that the agent kept trying to compensate for |
| A particular AI agent run was slow | The underlying agent was stuck in a recovery pattern triggered by an upstream retrieval quality issue, and the cost overrun on that run is structurally connected to the latency |
| This model is showing degraded answer quality | By following the trace through context assembly, we can see that chunks are being returned from a stale index in the retrieval layer, meaning that the model is performing exactly as expected given the inputs it received. The failure is in the data layer; the symptom presented in the application layer |
Of course, it’s easy enough to look at the right-hand column and notice that there are more words. But, importantly, observability is not simply “more complicated monitoring,” and this is the gap that the previous post’s signal taxonomy was pointing at. Quality, cost, and safety signals only become actionable context for AI agent debugging when you can trace them back through the stack to the layer where they originated (which can be quite distant from where the problems surfaced).
That capacity to trace — across agents, across layers, across the boundary between deterministic infrastructure and non-deterministic reasoning — is what observability adds to monitoring.
On its own, however, it’s not enough to get you all the way to finding and fixing errors in your multi-agent systems, because you still have the problem of figuring out what stands in most desperate need of remediation. It is to this that we turn in the next section.
The Three Issues Problem
Usually, the story people tell to motivate the need for observability is around lack of visibility, with the implication being that more instrumentation is the solution. But one thing this story leaves out is that comprehensive visibility creates its own problems.
When everything is instrumented and everything has an alert, engineers face an alert fatigue problem that monitoring has never solved. Even with sufficient observability, however, the list of potential issues can far exceed an engineer’s capacity for triage, shifting the bottleneck from figuring out what’s going wrong to determining what needs fixing first.
An engineer weaving agents into automated workflows can meaningfully investigate a small number of issues per day. In our experience, this number is around ‘three,’ though it varies as a function of many different factors. Meaningfully investigating an issue means reproducing the failure, tracing it through the stack, forming a hypothesis, testing it, and either fixing it or ruling out the hypothesis and starting again. That can easily add up to hours of work per issue.
This is a gap left unaddressed by most observability tooling, but intelligent prioritization — surfacing the issues most worth investigating based on their impact, recurrence, and resolvability — is what makes observability an asset in any AI troubleshooting playbook.
Without it, the dashboard is a more granular version of the problem. With it, the dashboard becomes a workflow someone can act on.
The market is starting to catch up
The shift toward remediation isn’t a thesis Prove AI is making in isolation; in recent reports, technology leaders ranked automated remediation near the top of the list of sources of the highest ROI from investment in AI observability platforms.
This is worth pausing on. These respondents are leaders at organizations that have already invested heavily in observability tooling, and, notably, they’re almost never saying they need more dashboards; they’re saying the next dollar of value is in closing the loop between detection and resolution. The category they’re pointing at doesn’t have a settled name yet, and terms like “automated remediation,” “AI-driven resolution,” and “intelligent triage” are all bandied about in the broader industry literature. Regardless of what nomenclature we eventually settle on, the core insight is that monitoring and observability are necessary but not sufficient for building the robust, high-quality, reliable AI systems we’re all so excited about.
Is observability enough for troubleshooting multi-agent AI systems?
As stated above, the ‘remediation’ category remains inchoate and poorly defined. Ultimately, however, cutting the Gordian knot of AI testing and debugging will require us to go beyond observability (as important as that is), availing ourselves of a mix of:
- Prioritizing across heterogeneous signals
- Root-cause analysis that crosses stack layers
- Resolution pathways that adapt to unanticipated failure modes
Let’s discuss these in more depth.
First, we need prioritized issue identification across the full observability stack. This means a ranking according to some metric of impact, recurrence, and resolvability. To furnish a sensible foundation for debugging automated workflows, this ranking has to work across layers, because a low-severity retrieval issue silently degrading three downstream agents can matter more than a high-severity application-layer error that’s already been routed to a fallback.
Then, we need contextual root-cause analysis going beyond “here’s where the failure surfaced” to tell you “here’s where it originated, here’s the path it took through the stack, and here’s what it’s affecting elsewhere.” Without that, the engineer’s investigation starts in the wrong place — and given the bounded investigation budget implied by the Three Issues Problem, starting in the wrong place is often tantamount to not investigating at all.
Finally, we need guided resolution pathways that move from “here’s everything happening, good luck” to “here’s what to fix first, here’s why, and here’s whether the fix worked.” Here at Prove AI, our more recent efforts have focused on functionality to handle this; we’re working on much more granular root-cause analysis that singles out individual, problematic edges in the agent graph, for example, allowing you to zero in on the place where things started going sideways.
Eventually, we want to build an engine to proactively find and fix any bugs before they are shipped into production, on the thesis that intelligent vetting of non-deterministic systems will make the need for remediation less acute and, therefore, less reactive. More specifically, our current offering can “freeze” certain aspects of the agent chain while leaving you free to make small modifications to others (e.g., swapping out a new tool or modifying a prompt). Then, you can replay just the new segments to test how changes redound throughout the rest of an automated workflow, which improves latency and lowers token costs.
Watch this space for more updates as they become available 🙂.
The convergence ahead
As things stand, observability is poised to expand well beyond its traditional perimeter; the implication for AI observability specifically is that the instrumentation engineers build for debugging quality regressions is becoming the same instrumentation that compliance teams use for audit trails, that finance teams use for unit-cost analysis, and that product teams use to connect model behavior to user outcomes. AI observability, in other words, is becoming a shared intelligence layer — one set of traces, signals, and evaluations serving multiple constituencies, each with their own version of the prioritization problem and their own definition of what “fixed” means.
But, if observability data is going to inform decisions across security, sustainability, business outcomes, etc., the prioritization and resolution capabilities that translate data into action have to scale with it. The Three Issues Problem isn’t unique to engineers; every constituency that consumes observability data eventually faces some version of it. The tooling that solves it for engineering will be the tooling that solves it for everyone else.
Where the series lands
The arc this series has traced is a single argument made in six parts. The shift from deterministic to non-deterministic systems forced a new observability stack into existence. That stack distributes responsibility across layers — compute, foundation models, data and context, evaluation, orchestration, application — that previously belonged to different teams or didn’t exist at all. OpenTelemetry has emerged as the connective tissue holding the stack together, but its job ends where evaluation begins, and the signals that matter most for AI systems — quality, cost, safety — require instrumentation that goes beyond what traditional APM was built to capture. In multi-agent AI systems, those signals fragment further across tool calls, sub-agents, and retrieval steps, producing failure modes that no single dashboard surfaces and that no engineer can investigate at the rate they’re produced.
The industry response to that final problem is what is driving the shift from monitoring through observability toward remediation. That’s the ground the series has covered, and it’s the ground Prove AI is built on.
From here, we want to move from the foundations into the practice; follow this space for updates as they arrive, and don’t hesitate to reach out if you’d like to chat with our team!
Frequently asked questions
Prove AI is building solutions to power more correct, explainable and auditable AI outcomes.
We’re always interested in learning about AI management challenges.
Get in Touch

