If you’ve instrumented an LLM system recently, you’re likely already aware of how much telemetry the observability stack can offer you: latency per completion call, token throughput, retrieval latency from your vector store, and error rates across every service boundary.
The instrumentation works, the data flows, the dashboards populate, and then…your system hallucinates confidently on every third request, with all of the metrics above remaining stubbornly silent about it.
This is the measurement problem that traditional observability engineering doesn’t solve because it was designed for a different question. Traditional observability asks: is the system up, is it fast, is it throwing errors? Those are threshold questions against deterministic behavior. AI systems require a different question entirely: is the output any good? That’s much more subtle than monitoring a threshold, requiring continuous, context-dependent judgment that doesn’t map onto latency percentiles or 5xx rates.
The previous post in this series covered how OTel collects and propagates signals through AI systems. This one covers what to measure, and why those specific things should be your focus.
One thing before we go any further: the argument here isn’t that infrastructure signals are now irrelevant. GPU utilization, memory pressure, service latency, error rates, and the panoply of other numbers you track remain both valid and necessary. What changes is that those signals are not enough, on their own. AI observability extends traditional observability with new signal categories that have no real precedent in deterministic software.
With that in mind, let’s get into the metrics side of AI observability engineering, including cost attribution, tracking issues like prompt regression, AI agent monitoring, and all the rest.
Traditional signals and their limits in AI systems
People have different ways of defining the canonical observability signal types, but metrics, logs, and traces are a standard way of doing it. These continue to work as designed in AI agent systems, with traces capturing every span from user request to completion response, logs recording the documents your retrieval pipeline returned, metrics tracking your inference endpoint’s p99 latency, and so on.
These mechanisms are sound, but they lack the resolution to detect the quality of reasoning that occurred between input and output. Consider, for example:
- A trace confirming that a completion call returned in 340 milliseconds (while communicating nothing about whether the response was accurate)
- A log capturing a retrieved document (without telling you whether that document was relevant to the question that was asked)
- An error rate of zero (in a system that’s confidently producing total nonsense in response to every request)
This is a structural gap; traditional signals measure the mechanism of computation (did the function execute, how long did it take, what did it return), but AI signals have to measure the output of reasoning (was the response correct, was it grounded, was it appropriate). These are different problems, and they require different instrumentation.
This is why evaluation has emerged as a distinct layer in the AI observability stack. It’s not a replacement for tracing, it’s a required complement to it. More on that shortly.
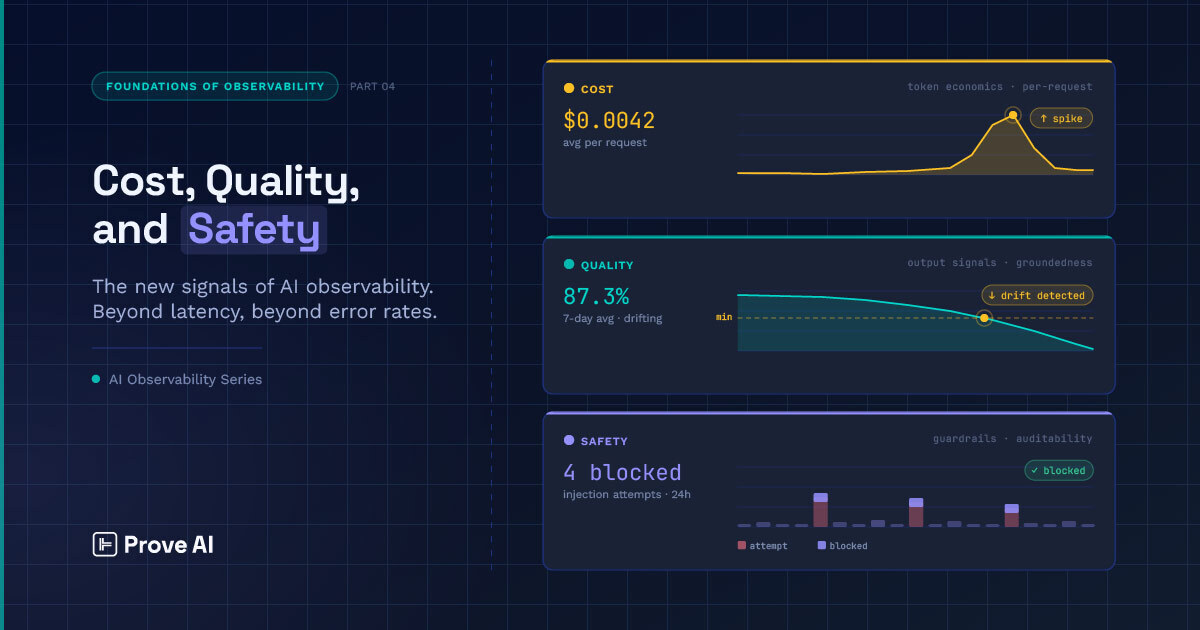
Token economics — cost as a live operational metric
In traditional software, compute cost is generally a billing artifact. You pay at the end of the month, review it quarterly, and optimize when this particular budget item gets uncomfortable. In LLM systems, cost is a per-request operational signal, and that distinction matters in ways that might not be obvious at first.
Recall that LLM providers charge per token. Every completion call has immediate cost attribution (usually prompt tokens plus completion tokens), which is priced per model, per provider, per request. At low volume, this is a footnote, but at production scale, it balloons into a first-class operational concern requiring the same instrumentation discipline you’d apply to any other critical metric.
The signals worth tracking include:
- Token counts per request: the number of tokens involved in completing a specific request. This should be broken out by prompt and completion. Prompt tokens are largely under your control through prompt engineering; completion tokens are partly determined by what the model decides to say. Tracking these separately tells you different things about what exactly is generating your costs.
- Cost attribution: figuring out what’s being spent at the request, user, feature, and agent-run level. Without this granularity, you can’t distinguish a user behavior problem from a prompt engineering problem from a model that’s gotten more verbose over time. Over-aggregating cost figures obscures the signal and will thwart your remediation efforts.
- Budget alerting: cumulative cost tracked against configurable thresholds, alertable in real time. This is a routine operational requirement in any system where unchecked consumption produces unbounded spend.
- Token efficiency ratios: the ratio of usable output to all the tokens consumed. This connects to the measurement framework discussed in the next section; the point here is that cost shouldn’t be tracked in isolation from the value it produces.
That last point reflects something practitioners discover quickly in production: cost anomalies are often failure signals before quality metrics catch them. An agent loop that runs longer than expected — thereby consuming more tokens across more steps than it should — might indicate a reasoning problem upstream. The cost spike is the early warning; the quality degradation follows. Treating cost as a pure billing concern means missing this diagnostic signal entirely.
For teams running multi-model setups, a normalized cost layer across providers simplifies attribution considerably — otherwise you’re reconciling per-token pricing across different provider schemas, which is not much fun.
Output quality — measuring what the system was actually built to do
Quality, of course, is harder to measure than cost. Cost is a number; quality is a judgment. But “harder to measure” doesn’t mean “impossible to operationalize,” of course, and the patterns for doing so have become fairly well-established across system types.
Quality signals vary by what kind of system you’re instrumenting:
- RAG pipelines have the most tractable quality signals because retrieval provides a ground-truth reference point. The key measures: retrieval accuracy (did the right documents come back?), context relevance (were the retrieved documents actually useful for the question asked?), answer faithfulness (does the generated response stay grounded in what was retrieved?), and groundedness scores that penalize claims the retrieved context doesn’t support.
- Generative completions without a retrieval component are harder. Here the signals shift toward relevance to intent, factual accuracy where verifiable, response coherence, and output length appropriateness — all of which require either a reference answer, a scoring model, or LLM-as-judge evaluation.
- Agent outputs introduce a third category: task completion rate, reasoning coherence across steps, and tool selection accuracy. Whether the agent accomplished what it was asked to do is often the most important quality signal, and it typically requires evaluation at the run level rather than the individual completion level.
AI hallucination deserves specific treatment because it’s not a uniform failure mode. A fabricated proper noun in a customer-facing response is categorically different from a reasonable extrapolation in an analytical context; a confident misattribution in a regulated domain is different again. Detection approaches — retrieval-grounded scoring where you have reference documents, LLM-as-judge evaluation for open-ended output, reference comparisons where ground truth exists — have different applicability depending on which failure mode you’re most exposed to.
Semantic drift and model degradation make all of this trickier still, because they mean that output quality isn’t static. Models receive updates, prompts age against shifting user behavior, fine-tuned models drift from their evaluation distributions over time, etc. Quality metrics tracked as point-in-time snapshots will miss gradual degradation that becomes obvious only in retrospect. This is where the monitoring-to-observability distinction becomes concrete: monitoring tells you today’s quality score; observability lets you see the trend, identify when it changed, and trace it back to what caused it.
This points to a measurement principle that practitioners working across AI observability tend to converge on independently: performance, cost, and quality must be tracked together, because they trade against each other (i.e., switching to a smaller model to reduce latency typically degrades output quality). The signals are interdependent, and the instrumentation has to treat them that way.
Safety and governance — the trust layer
Safety signals are distinct from quality signals in a way that’s worth making explicit. Quality asks whether an output is good; safety asks whether it’s appropriate, unbiased, and traceable. These aren’t the same question, and they don’t share the same instrumentation.
The signals required to engineer trust in AI observability engineering include:
- Prompt injection detection. As AI systems ingest user-supplied content and participate in multi-agent handoffs, the surface area for adversarial inputs expands. Monitoring for inputs that attempt to override system behavior — directly or through embedded instructions in retrieved content — is an operational requirement, not a post-launch consideration.
- Bias and harm detection. Output scoring against configurable guardrails. The criteria vary significantly by domain: what constitutes harmful output in a customer service context differs from a medical context or a legal one. The instrumentation pattern is similar across domains, but the threshold configuration is specific to the use case.
- Auditability. Every decision is traceable to its inputs, context, and model state at the time the output was generated. This is the observability requirement that governance frameworks actually impose. Regulatory frameworks like the EU AI Act create traceability obligations that can’t be met with monitoring dashboards alone, requiring the kind of provenance that full observability infrastructure provides.
- Guardrail performance. Guardrails have false positive rates. An overly aggressive filter that blocks legitimate requests is itself a failure mode, one worth tracking with the same discipline as the harms it’s meant to prevent. If your safety layer is producing false positives at scale, that signal belongs in your observability stack.
The upshot of all this is that teams deploying AI in production are navigating a genuine trust gap. The path from “human reviews everything” to graduated, policy-based trust runs through auditability because you can’t extend trust to a system whose behavior you can’t retrospectively verify. Closing that gap is an observability problem.
The evaluation layer — continuous quality assessment
Traditional software correctness is binary: the function returns the right value or it doesn’t. The test suite tells you whether it passed. AI output correctness is probabilistic and context-dependent; the test suite model doesn’t transfer.
AI evaluation frameworks such as Ragas, LLM-as-judge patterns, and hand-rolled scoring pipelines have emerged as the practical response. The pattern revolves around defining evaluation criteria appropriate to your use case, running assessments continuously against live or sampled output, and feeding those results back as operational signals alongside the infrastructure metrics you’re already collecting.
This also points to what makes agentic systems the hardest observability problem in the current stack — evaluation has to occur at the “reasoning” level, meaning across chains of decisions with no single point of failure to isolate. That’s the subject of Part 5.
What the signal expansion actually represents
Bringing these three signal categories together — cost, quality, safety — doesn’t just make AI observability wider than traditional observability (more layers to instrument), it also makes it deeper: new signal types at every layer, including signals that require interpretation rather than measurement.
What this means is that teams approaching AI observability as “add dashboards to existing monitoring” might well end up with fast, low-error systems that hallucinate reliably, accumulate unpredictable costs, and produce outputs they can’t retrospectively audit. Teams that instrument cost, quality, and safety as first-class operational signals have something more useful: the foundation for knowing which problems actually deserve attention.
That’s where the instrumentation story leads. Once you have these signals, the next question is prioritization: you can’t investigate every quality degradation event or cost anomaly simultaneously; deciding what surfaces first, what can wait, and what the cost of waiting is.
That problem has a shape, and it’s what the rest of this series is built around.
Frequently asked questions
Prove AI is building solutions to power more correct, explainable and auditable AI outcomes.
We’re always interested in learning about AI management challenges.
Get in Touch

