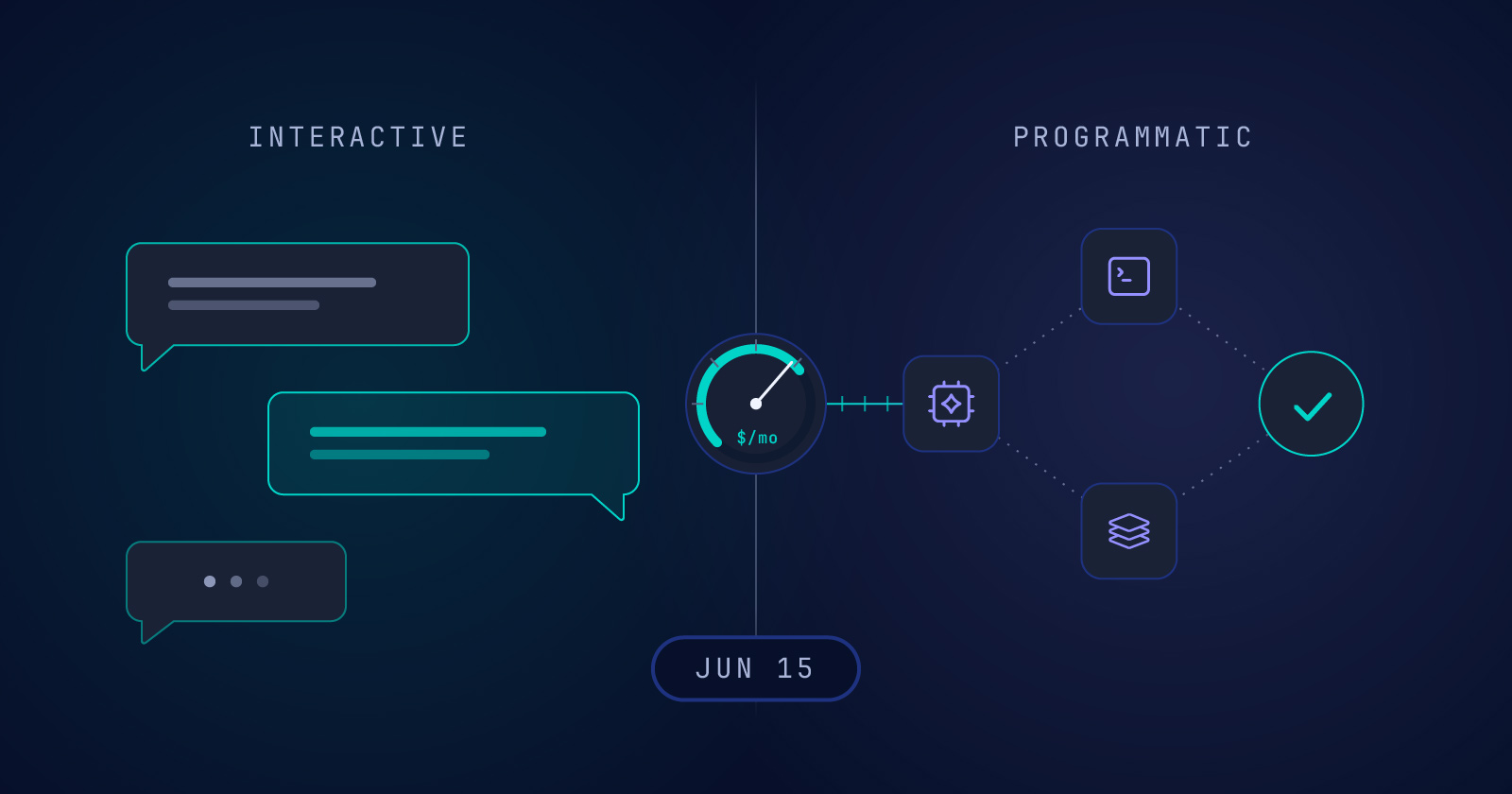
On June 15, 2026, Anthropic plans to change how its subscriptions handle billing for certain types of Claude usage. Key services such as the Claude Agent SDK, the claude -p command, the Claude Code GitHub Actions integration, and third-party apps that use your subscription for authentication are moving to a separate monthly Agent SDK credit. Once that credit is exhausted, usage will continue at standard API rates through usage credits; if usage credits aren’t enabled, requests will stop until the credit refreshes.
What’s more, the relevant credit amounts are fixed on a per-user basis:
| Plan | Monthly Agent SDK credit |
|---|---|
| Pro | $20 |
| Max 5x | $100 |
| Max 20x | $200 |
| Team (Standard seats) | $20 |
| Team (Premium seats) | $100 |
| Enterprise (usage-based) | $20 |
| Enterprise (seat-based Premium seats) | $200 |
For their part, use cases such as interacting with Claude Code through the terminal or IDE, chatting with Claude via the web, desktop, and mobile interfaces, and using Claude Cowork will remain exactly as they are, subject to existing subscription limits.
There are a few steps you can take now, and which is best for you will depend upon whether you’re an individual or part of a team.
- For individuals: claim the credit when the email arrives, and decide whether to enable usage credits — that toggle determines whether you overflow into API billing or hit a hard stop.
- For teams: audit which automations authenticate through a subscription versus an API key, move shared production workloads to API keys with spend controls, and treat context and state management as a cost lever, not just a reliability one.
Bear in mind that API key users on the Claude Platform receive no credit, and pay-as-you-go billing remains unchanged; members of seat-based Enterprise plans on Standard seats aren’t eligible to claim the credit.
Having covered the mechanics of this pricing change, the next few sections will take a broader view of its implications.
Why this matters beyond pricing
On one level, this is a basic pricing adjustment, but it can also be read as a step towards a new pattern wherein AI usage within companies is gradually splitting into two operating modes:
- Conversational usage, in which humans interact with models directly (e.g., via chatbots).
- System usage, in which models embedded inside workflows, tooling, and autonomous pipelines produce work without a human in the loop (automated workflows, multi-agent systems, and the like).
- Claude web, desktop, mobile chat
- Interactive Claude Code (terminal/IDE)
- Claude Cowork
- Claude Agent SDK (your projects)
claude -p(non-interactive)- GitHub Actions + third-party agent apps
It would be natural to think of these as “chat” and “code,” but it’s more productive to frame this split as being between interactive and non-interactive surfaces.
A lot of the AI spend emerging inside companies such as Prove AI (and probably yours as well) isn’t coming from overzealous use of chat interfaces, it’s coming from things like automated AI coding agents, CI/CD-integrated workflows, batch evaluation and generation pipelines, tool-using agents embedded in internal systems, and everything else that makes AI agent debugging so difficult. These applications are becoming more like infrastructure, and infrastructure behaves differently once it becomes measurable.
Anthropic’s own admin guidance points the same direction: the Agent SDK credit is “sized for individual experimentation and automation,” and teams running shared production automation “should use Claude Platform with an API key for predictable pay-as-you-go billing.” In other words, the change nudges production automation off subscription seats and onto metered API billing, where cost is observable and attributable. For organizations, that’s mostly good AI governance, as it restores visibility into your AI agents that subscription-funded automation quietly occluded. For individuals and small teams who built on subsidized subscription rates, it ends a period of accidental arbitrage. The credit cushions the transition, but it doesn’t change where we’re all going.
There’s an underrated upside in that. A fixed, per-user credit is predictable in a way that an uncapped subscription draw never was. You know your floor, you know your overflow rate, and you can instrument against both.
What are the hidden costs of AI agent automations?
When AI agent workflows are lightweight or low-stakes, inefficiency is invisible. You retry, you tweak prompts, you rerun the task, and nothing feels structurally wrong. But as usage scales — especially in code generation, refactoring, and automated tooling — inefficiency compounds enough to start drawing your attention. The same context gets reloaded repeatedly, the same mistakes get rediscovered across runs, agents loop instead of converging, and human oversight increases instead of decreasing. After realizing that small problems can compound into major failures across multi-agent systems, we at Prove AI have been building observability solutions for this problem. You can fix what you can’t see, and our bet is that agentic observability will be a critical part of the toolchain for those present and future organizations attempting to roll out robust, valuable automated workflows.
With this billing change, an agent that’s spinning its tires now shows up as a line item. The cost signal has always manifested in more ephemeral considerations like debugging time, overall predictability, and the trust you have in the systems, but the June 15 shift will now attach a meter to it.
Why does multi-agent reliability break down at scale?
Teams might fail because the model “isn’t smart enough,” but it’s much more common for them to fail because the surrounding system is itself unstable. Once you move from occasional prompting to real multi-agent workflows (i.e., those built around coding agents, CI automation, multi-step tool use), the limiting factor shifts away from intelligence and toward consistency.
What breaks first is generally not reasoning quality, it’s continuity; there are many ways this can show up, but you’ve no doubt already run into context that no longer reflects the current codebase, AI agents duplicating work, tools operating with slightly different assumptions, instructions that accumulate and quietly contradict each other, workflows that succeed once then fail unpredictably under similar conditions, and similar sorts of issues that emerge from the inherently non-deterministic nature of the underlying systems.
At that point, debugging stops being about prompts and becomes about system state, and system state, in most teams, is still informal, living in scattered context files, ad hoc instructions, chat history, and whatever the agent last happened to see.
Who will feel it first?
The impact won’t be uniform. Teams that treat AI as a general-purpose productivity booster will mostly see minor adjustments.
The real pressure shows up in teams that have leaned heavily into automation without formalizing how those systems stay consistent over time — multiple agent tools touching the same codebase, workflows that rely on large unstructured context dumps, limited versioning or traceability of instructions, and systems that depend on “just rerun it” as a recovery strategy.
The underlying shift
What’s happening is a gradual reclassification of AI usage inside companies from a tool to a system (or “infrastructure,” as we said above). Once that happens, the questions will change, moving from “are the outputs good” to “are these workflows stable”, and from “are the models performing” to “do the different parts of these systems reliably converge over time?” That forces teams to confront something many have been putting off — the need to explicitly manage context as part of the engineering stack. Redundant context reloading and pointless agent looping have long been a reliability problem, but now they’ll be metered, too. Tightening context management, therefore, is no longer about basic hygiene and will soon be something that directly impacts the all-important bottom line.
As AI systems move deeper into production workflows, their long-hidden costs are becoming visible, not just in pricing, but in reliability, coordination, and operational overhead. Most teams will feel this first as unpredictability, but the ones who adapt earliest will need to treat it as an engineering problem. The real advantages will accrue to those who know how to structure context, state, and workflow so agent systems behave consistently as they scale.
That’s the future we’re building for at Prove AI; we encourage you to check out our repository (which contains a ready-made observability pipeline and a whitepaper), or get in touch if you want to chat with our team!
Frequently asked questions
Prove AI is building solutions to power more correct, explainable and auditable AI outcomes.
We’re always interested in learning about AI management challenges.
Get in Touch

